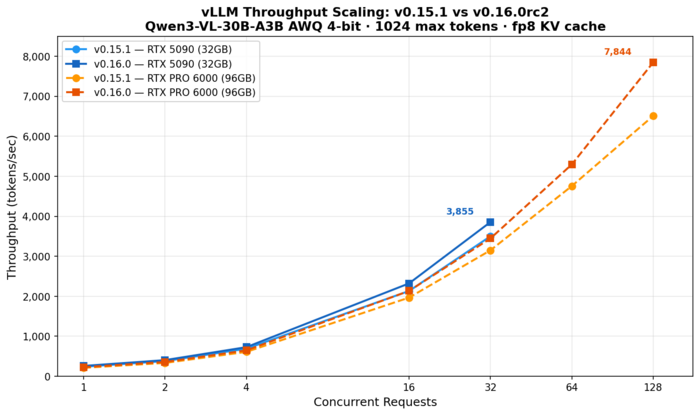
vLLM v0.16.0 is shaping up to be a meaningful performance release. We benchmarked the release candidate against the current stable v0.15.1 on two NVIDIA Blackwell GPUs — an RTX 5090 (32GB) and an RTX PRO 6000 (96GB) — running a 30-billion-parameter vision-language model. The results: 8–10% higher throughput at moderate concurrency, and a 20% throughput gain at 128 concurrent requests on the RTX 6000, where v0.16 pushes nearly 7,900 tokens per second from a single GPU.
Setup
Model: Qwen3-VL-30B-A3B-Instruct, quantized to 4-bit AWQ (cpatonn/Qwen3-VL-30B-A3B-Instruct-AWQ-4bit). This is a Mixture-of-Experts vision-language model with 30B total parameters and 3B active, making it a practical choice for single-GPU deployment.
Hardware: Two Blackwell-generation GPUs in a single workstation — an RTX 5090 (32GB GDDR7, 21,760 CUDA cores, 575W) and an RTX PRO 6000 Max-Q (96GB GDDR7 with ECC, 24,064 CUDA cores, 300W). The 6000 has 10% more cores and 3x the memory, but runs at roughly half the power envelope, which limits effective clock speeds. Both share the same 1,792 GB/s memory bandwidth on a 512-bit bus.
Software: vLLM v0.15.1 (stable, vllm/vllm-openai:latest) vs v0.16.0rc2 (pre-release, built locally with a MoE weight loading fix). Both configured with fp8 KV cache, prefix caching enabled, and max-model-len=16384.
Methodology: For each GPU/version combination, we sent batches of concurrent requests at concurrency levels 1, 2, 4, 16, and 32 (max-num-seqs=32). We then ran a separate high-concurrency pass on the RTX 6000 at concurrency 64 and 128 (max-num-seqs=128) to test how far the 96GB VRAM could push throughput. Each request asked for a 1024-token story about a different animal. Throughput is measured as total tokens generated divided by wall-clock time for the entire batch.
Sequential Baseline
In our earlier sequential benchmark (one request at a time, max-model-len=131072), v0.16.0rc2 produced 259.3 tok/s versus 241.0 tok/s for v0.15.1 on the RTX 5090 — a 7.6% improvement. This established that v0.16 has a real per-request decode speed advantage, not just better batching.
Parallel Throughput Results
Here’s the main event — total throughput (tokens/second) at each concurrency level:
| Concurrency | v0.15.1 5090 | v0.16.0 5090 | v0.15.1 6000 | v0.16.0 6000 |
|---|---|---|---|---|
| 1 | 238 | 259 | 211 | 228 |
| 2 | 379 | 404 | 334 | 357 |
| 4 | 689 | 728 | 610 | 648 |
| 16 | 2,132 | 2,322 | 1,967 | 2,134 |
| 32 | 3,500 | 3,855 | 3,149 | 3,446 |
| 64 | — | — | 4,755 | 5,295 |
| 128 | — | — | 6,508 | 7,844 |
(Concurrency=8 omitted due to a torch.compile warmup stall. The c=64 v0.16 result was re-verified with a warmup batch for accuracy.)
At moderate concurrency (1–32), v0.16.0rc2 delivers a consistent 8–10% throughput improvement on both GPUs. At c=32 on the 5090: 3,855 vs 3,500 tok/s (+10.1%). On the 6000: 3,446 vs 3,149 tok/s (+9.4%).
The real story emerges at high concurrency on the RTX 6000, where 96GB of VRAM can sustain 128 simultaneous sequences. At c=128, v0.16.0rc2 hits 7,844 tok/s — a 20.5% improvement over v0.15.1’s 6,508 tok/s. This suggests v0.16’s scheduler and batching improvements compound at scale, delivering gains well beyond the 8–10% seen at lower concurrency.
Both GPUs show excellent scaling overall. The 5090 goes from 238 tok/s at c=1 to 3,855 at c=32 — a 16.2x throughput multiplier. The 6000 scales even further, from 228 tok/s at c=1 all the way to 7,844 at c=128 — a 34.4x multiplier. Average per-request latency at c=128 is 16.6s on v0.16, a reasonable trade-off for nearly 8K tok/s aggregate throughput.
5090 vs 6000
At low-to-moderate concurrency (1–32), the RTX 5090 is consistently 11–13% faster than the RTX PRO 6000, despite having fewer CUDA cores. The 5090’s 575W power budget lets it sustain higher effective clocks than the 6000 Max-Q’s 300W limit — nearly double the thermal headroom translates directly to higher per-request decode speed.
But the tables turn at high concurrency. The 5090’s 32GB VRAM caps out around c=32 with max-num-seqs=32, while the 6000’s 96GB can comfortably serve 128 simultaneous sequences. At c=128, the 6000 delivers 7,844 tok/s with v0.16 — more than double the 5090’s peak of 3,855 at c=32. For workloads prioritizing total throughput over per-request latency, the 6000’s memory advantage is decisive.
Caveats
A few important notes. First, v0.16.0rc2 is a pre-release — we had to build the image locally and apply a fix for a MoE weight loading bug (PR #35305). Second, v0.16 required setting FLASHINFER_DISABLE_VERSION_CHECK=1 to start. Third, we hit a torch.compile cache issue when switching between GPUs — compiled CUDA graphs from the 5090 caused assertion failures on the 6000 due to different KV cache block counts. Clearing ~/.cache/vllm/torch_compile_cache/ resolved it, but it’s worth noting for anyone running v0.16 across heterogeneous GPU setups. Finally, v0.16’s torch.compile can cause a one-time throughput dip at certain batch sizes during the first run after startup, as CUDA graphs are captured on the fly. We omitted the anomalous concurrency=8 results and re-verified c=64 with a warmup batch to ensure accuracy.
Conclusion
vLLM v0.16.0rc2 delivers 8–10% higher throughput at moderate concurrency and up to 20% at high concurrency, tested across two Blackwell GPUs. The RTX 5090 peaks at 3,855 tok/s serving 32 simultaneous requests, while the RTX 6000’s 96GB of VRAM unlocks a new tier — 7,844 tok/s at 128 concurrent requests, more than double the 5090’s best. For teams running quantized MoE models in production, v0.16 is a meaningful upgrade — and for anyone with high-VRAM workstation GPUs, the scaling headroom at high concurrency is the real headline. We’re looking forward to the stable release.