TL;DR: We benchmarked three popular LLM inference backends—vLLM, SGLang, and Ollama—running Llama 3.1 8B on an NVIDIA RTX PRO 6000 Blackwell Max-Q GPU (96GB VRAM).
Key Takeaways:
- The Speed King: vLLM using NVIDIA’s NVFP4 quantization hit 8,033 tokens/second, the highest throughput recorded.
- The Efficiency Winner: When comparing identical model formats (GPTQ-INT4), SGLang beat vLLM by 17%, reaching 6,395 tokens/second.
- The Local Option: Ollama remains the easiest to use but is significantly slower for production, topping out at 484 tokens/second (approx. 10x slower than dedicated servers).
- Reliability: Only vLLM and SGLang maintained 100% success rates at 128 concurrent requests; Ollama broke down under this load.
The Setup
Choosing the right backend can make or break your AI application. We pushed three contenders to their limits on a beastly NVIDIA Blackwell workstation.
The Hardware
- GPU: NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition (96GB VRAM)
- CPU: Intel Core Ultra 7 (96GB RAM)
- OS: Ubuntu Linux 24
The Contenders
- vLLM: The production standard, tested with both NVFP4 (NVIDIA’s optimized quantization) and GPTQ-INT4.
- SGLang: LMSYS’s structured generation engine, tested with GPTQ-INT4.
- Ollama: The local development favorite, tested with standard llama3.1:8b (INT4).
The Results
1. Peak Throughput Comparison
The raw power difference is stark. vLLM with NVFP4 dominates, but SGLang puts up an impressive fight against vLLM’s standard GPTQ implementation.
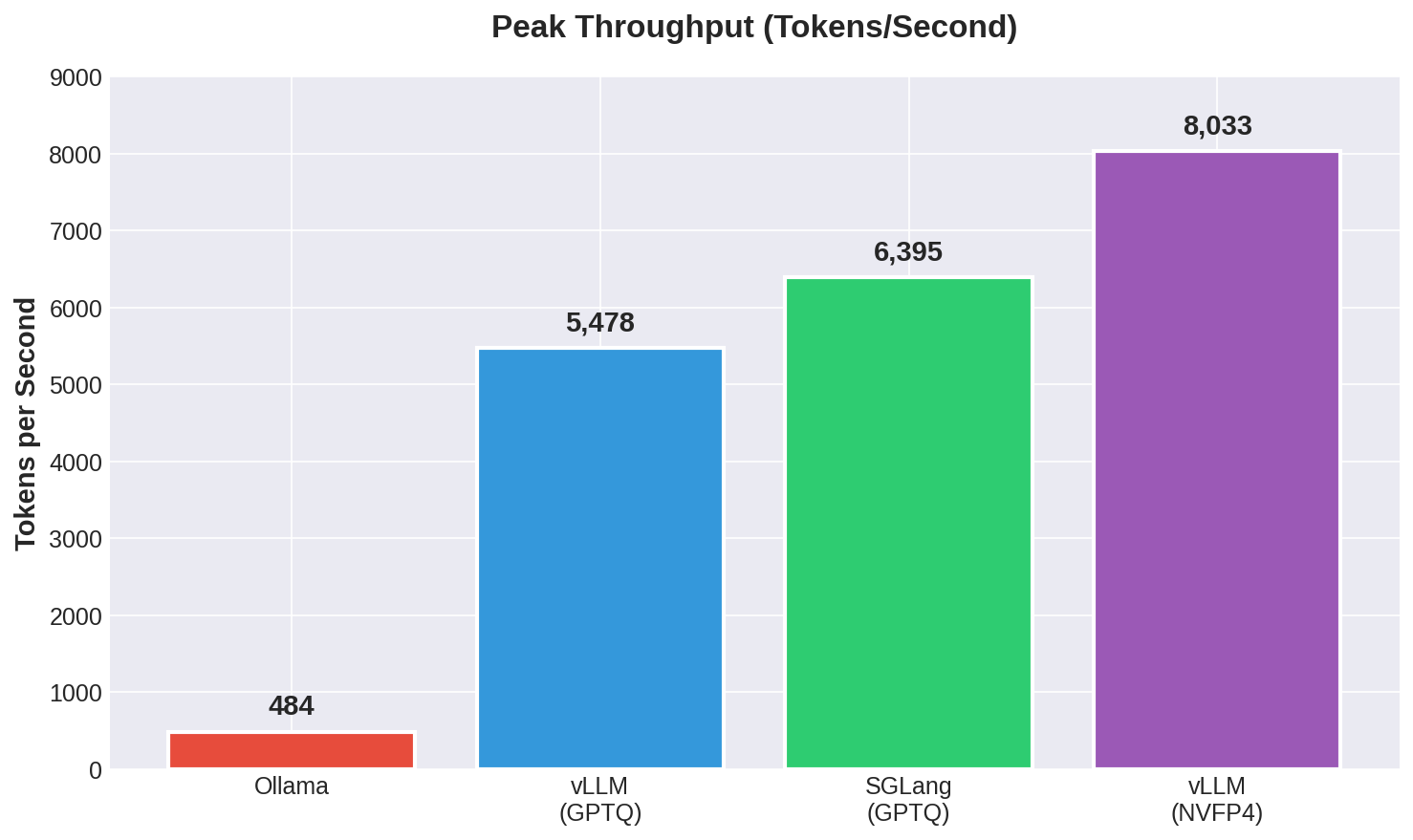
Figure 1: Maximum throughput achieved at peak concurrency. vLLM (NVFP4) leads the pack, but SGLang outperforms vLLM when using the same GPTQ format.
2. Apples-to-Apples: SGLang vs. vLLM (GPTQ)
When we level the playing field by using the exact same GPTQ-INT4 model, the dynamic shifts. SGLang consistently outperforms vLLM across almost all concurrency levels.
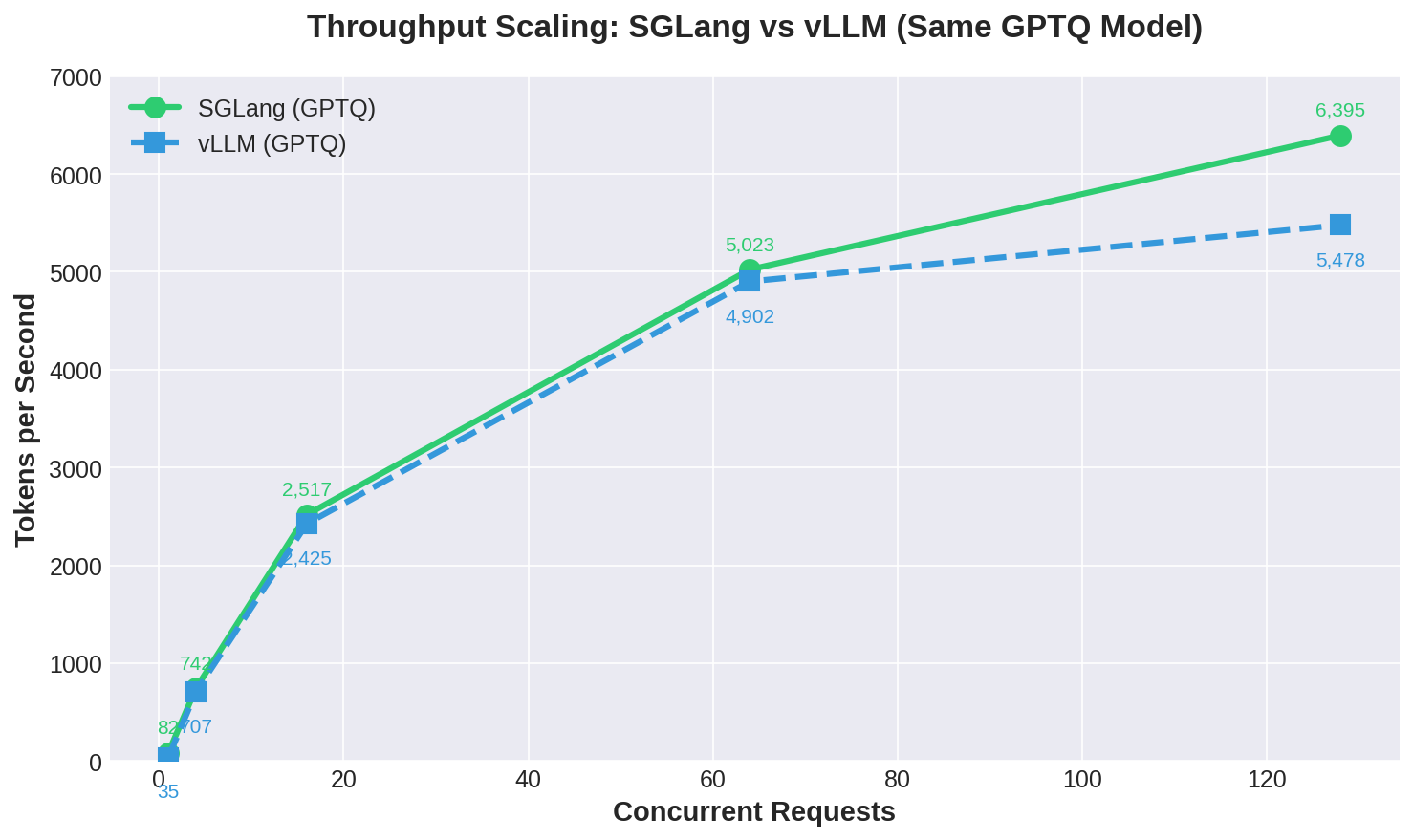
Figure 2: Throughput scaling. SGLang maintains a lead over vLLM as concurrency increases, widening the gap to 17% at 128 requests.
3. Time to First Token (TTFT)
Latency is critical for user experience. We measured TTFT at concurrency=1:
| Backend | Model | Avg TTFT |
|---|---|---|
| vLLM | GPTQ-INT4 | 10.7ms |
| vLLM | NVFP4 | 13.8ms |
| SGLang | GPTQ-INT4 | 14.2ms |
| Ollama | INT4:Q4_K_M | 65.0ms |
Table 1: Time to first token after warmup. vLLM (GPTQ) is the fastest at 10.7ms—6x faster than Ollama.
4. Reliability Under Load
At 128 concurrent requests, vLLM and SGLang both maintained 100% success rates. Ollama broke down.
Deep Dive: Why the Differences?
vLLM’s Hardware Advantage
vLLM’s victory with NVFP4 isn’t just about software; it’s about hardware synergy. NVIDIA’s FP4 quantization packs more parameters into memory, and vLLM’s CUDA graph support on Blackwell processors allows it to extract maximum throughput.
SGLang’s “Apples-to-Apples” Efficiency
SGLang’s architecture is highly optimized. It won 6 out of 8 concurrency levels against vLLM when using the same model.
Note: We had to run SGLang with
--disable-cuda-graphdue to a compatibility issue with the Blackwell SM-120 architecture. We used thelmsysorg/sglang:blackwellcontainer, and despite multiple internet sources claiming NVFP4 support, we were unable to get it working. Once SGLang patches this, we expect its performance to jump even higher.
Ollama’s Trade-off
Ollama optimizes for Developer Experience (DX), not raw server throughput. Its single-command setup is unbeatable for prototyping, but it lacks the sophisticated batching required for high-load production.
Ollama’s TTFT of 65ms is slower than vLLM/SGLang but still responsive for interactive use.
Final Verdict
| If you need… | The Winner is… |
|---|---|
| Maximum Production Throughput | vLLM (with NVFP4) |
| Broad Model Support & Efficiency | SGLang (with GPTQ) |
| Rapid Prototyping / Local Dev | Ollama |
Our Hybrid Approach
We have decided to use vLLM with NVFP4 for our high-throughput production inference and keep Ollama for local development and model switching.
Benchmarks conducted January 2026. Llama 3.1 8B. Request pattern: “Write a 1000 word story about {animal}” with varying animals across concurrent requests.