
TL;DR
Tested GLM-4.7-Flash with NVFP4 and AWQ quantizations on an RTX 5090. NVFP4 wins on accuracy (71.5% vs 69.4% MMLU, 82.4% vs 80.9% GSM8K). AWQ wins on speed (6-17% faster depending on load).
For throughput, max-num-seqs is the key bottleneck. With seqs=16, both plateau at ~1,300 tok/s. Bump to seqs=64 and throughput scales to 4,381 tok/s—over 3x higher. The catch: higher concurrency requires more KV cache memory, so I had to cut context length from 8k to 2k tokens. It’s a trade-off between concurrent users and context length.
vLLM crushes Ollama on throughput (4,381 vs 467 tok/s at scale). SGLang 0.5.8 doesn’t work with GLM on Blackwell—NVFP4 produces garbage, AWQ crashes, FP16 OOMs.
Bottom line: Use vLLM. Pick NVFP4 for accuracy-sensitive tasks, AWQ for throughput. Tune max-num-seqs based on your context length needs.
Friday night. Forecast says dropping to ten degrees tonight. A snowstorm is rolling in tomorrow evening. News has been catastrophizing over that snow storm for the past few days so the world seems to have shut down early and I’ve got nowhere to be until Monday afternoon. Time to entertain myself and heat the house with more benchmarks. This time they are tunning on an RTX 5090 (32 GB VRAM and 600 W) and a Ryzen 9950X (~150W for the balance of system).
The new GLM-4.7-Flash was just released (this week’s hottest model, but it will change again next week…) The question on the table: does quantization method matter for GLM-4.7-Flash? Both NVFP4 and AWQ compress the model to 4 bits, but they use fundamentally different approaches. FP4 preserves floating-point semantics; AWQ uses integer quantization with learned scaling factors. Same bit-width, different math. Does inference engine matter - vLLM or Ollama or SGLang?
I set up vLLM on my RTX 5090 (32GB VRAM) with an AMD Ryzen 9 9950X and 192GB of RAM to start, then ran both quantizations through accuracy benchmarks and throughput scaling tests. Moved on to Ollama then finally SGLang.
The Models
| Model | Quantization | Source |
|---|---|---|
GadflyII/GLM-4.7-Flash-NVFP4 |
FP4 (NVIDIA) | HuggingFace |
cyankiwi/GLM-4.7-Flash-AWQ-4bit |
AWQ INT4 | HuggingFace |
Both are community quantizations of Zhipu AI’s GLM-4.7-Flash, a 30B parameter MoE model with only 3B active during inference.
Accuracy: MMLU and GSM8K
I ran lm_eval with the completions API (not chat—GLM generates chain-of-thought reasoning on chat that tanks benchmark scores).
MMLU (14,042 questions)
| Model | Accuracy | Total Time | Avg Time/Question |
|---|---|---|---|
| NVFP4 | 71.53% | 830.1s | 0.059s |
| AWQ | 69.41% | 651.9s | 0.046s |
NVFP4 wins on accuracy by 2.1 percentage points. AWQ processes questions 22% faster.
GSM8K (1,319 math problems)
| Model | Accuracy | Total Time | Avg Time/Question |
|---|---|---|---|
| NVFP4 | 82.41% | 978.5s | 0.74s |
| AWQ | 80.89% | 868.3s | 0.66s |
Same pattern: NVFP4 holds a 1.5 point accuracy advantage, AWQ is 11% faster.
The accuracy differences are small but consistent. FP4’s floating-point representation appears to preserve slightly more model fidelity than AWQ’s integer approach.
Throughput Scaling
Accuracy benchmarks run sequentially—one question at a time. Real workloads often have multiple concurrent requests. How do these quantizations scale?
I tested two configurations to understand how max-num-seqs affects scaling:
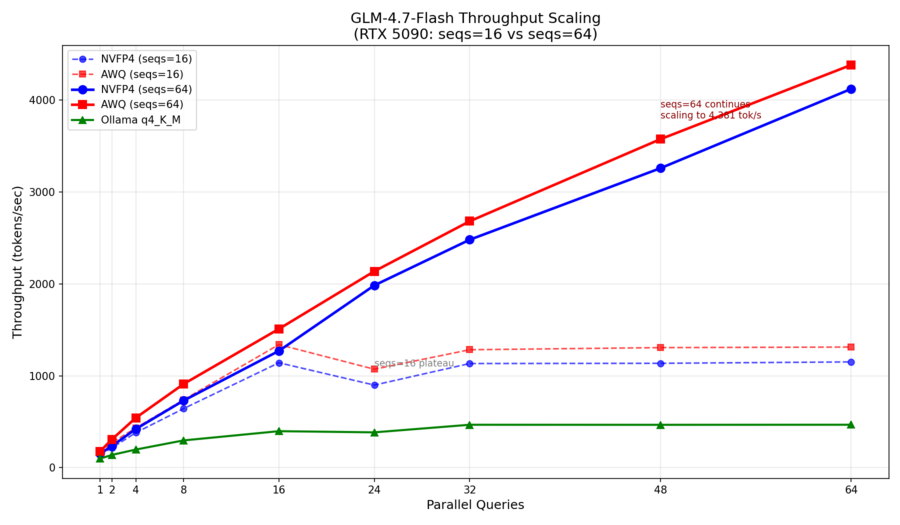
Configuration 1: max-num-seqs=16, max-model-len=8192
First test with longer context (8k) and conservative batch limits:
| Parallelism | NVFP4 (tok/s) | AWQ (tok/s) | AWQ Advantage |
|---|---|---|---|
| 1 | 140 | 160 | +14% |
| 8 | 643 | 739 | +15% |
| 16 | 1,141 | 1,339 | +17% |
| 32 | 1,133 | 1,283 | +13% |
| 64 | 1,151 | 1,312 | +14% |
Throughput plateaus after 16 parallel queries—the max-num-seqs=16 limit means additional requests just queue.
Configuration 2: max-num-seqs=64, max-model-len=2048
Second test with shorter context (2k) and higher batch limits:
| Parallelism | NVFP4 (tok/s) | AWQ (tok/s) | AWQ Advantage |
|---|---|---|---|
| 1 | 152 | 178 | +17% |
| 8 | 730 | 910 | +25% |
| 16 | 1,271 | 1,510 | +19% |
| 32 | 2,480 | 2,681 | +8% |
| 64 | 4,120 | 4,381 | +6% |
With max-num-seqs=64, throughput continues scaling to 4,381 tok/s—over 3x the seqs=16 configuration.
Key Observations
max-num-seqs is the bottleneck: The seqs=16 configuration plateaus at ~1,300 tok/s regardless of how many requests you throw at it. Bump it to 64 and throughput keeps climbing.
Trade-off: context vs concurrency: Higher max-num-seqs requires more KV cache memory. I reduced max-model-len from 8192 to 2048 to fit 64 concurrent sequences. For short-output workloads (chat, code completion), this is a good trade.
AWQ advantage narrows at scale: At low parallelism, AWQ is 17-25% faster. At 64 parallel queries, the gap shrinks to just 6%. The GPU becomes memory-bandwidth bound and both quantizations hit similar limits.
Peak throughput: AWQ hits 4,381 tok/s at 64 parallel queries. NVFP4 peaks at 4,120 tok/s. Both are remarkable for a single consumer GPU.
Ollama Comparison
How does vLLM compare to Ollama? I ran the same story generation benchmark using Ollama’s q4_K_M quantization of GLM-4.7-Flash.
| Parallelism | vLLM NVFP4 | vLLM AWQ | Ollama q4_K_M |
|---|---|---|---|
| 1 | 140 tok/s | 160 tok/s | 99 tok/s |
| 8 | 643 tok/s | 739 tok/s | 297 tok/s |
| 16 | 1,141 tok/s | 1,339 tok/s | 397 tok/s |
| 32 | 1,133 tok/s | 1,283 tok/s | 467 tok/s |
| 64 | 1,151 tok/s | 1,312 tok/s | 467 tok/s |
vLLM delivers 2.5-3x higher throughput than Ollama at scale. Ollama peaks at ~467 tok/s around 32 parallel queries, while vLLM hits 1,300+ tok/s.
The difference comes down to batching efficiency. vLLM’s continuous batching and optimized CUDA kernels (especially Marlin for AWQ) extract more parallelism from the GPU. Ollama is simpler to set up but leaves performance on the table.
For single-user, interactive use, Ollama’s 99 tok/s is plenty fast. For serving concurrent requests, vLLM is the clear winner.
Why vLLM Over SGLang?
SGLang 0.5.8 claims GLM-4.7-Flash support, so I tested it. The results were disappointing:
| Model | Result |
|---|---|
| NVFP4 | Loads but produces garbage output |
| AWQ | Crashes during load |
| Base FP16 | OOM (~31GB needed vs 32GB available so not applicable to consumer GPUs) |
The NVFP4 failure traces to a scale format mismatch—Blackwell’s DeepGemm expects ue8m0 format, but the checkpoint uses something different. The AWQ crash hits an MLA attention bug where ReplicatedLinear is missing a weight attribute.
Additional headaches: the glm4_moe_lite architecture required a nightly SGLang build plus a bleeding-edge transformers commit (PR #17247), and Triton hit shared memory limits on Blackwell (114KB required vs 101KB available).
Bottom line: vLLM’s TRITON_MLA backend properly handles GLM-4.7-Flash’s MLA architecture and quantization on Blackwell. SGLang’s support is incomplete.
The Trade-off
| Metric | Winner | Margin |
|---|---|---|
| MMLU Accuracy | NVFP4 | +2.1% |
| GSM8K Accuracy | NVFP4 | +1.5% |
| Single-query Speed | AWQ | +17% |
| Peak Throughput (seqs=64) | AWQ | +6% |
The choice depends on your priorities:
Choose NVFP4 if:
- Accuracy matters more than speed
- You’re running complex reasoning tasks
- You’re processing requests sequentially
Choose AWQ if:
- Throughput is your primary constraint
- You’re running batch workloads
- The ~2% accuracy drop is acceptable
At high concurrency (64 parallel queries), AWQ’s advantage shrinks to just 6%—the GPU saturates and both quantizations hit similar memory bandwidth limits. The accuracy gap matters more than the speed gap at scale.
Test Configuration
| Component | Specification |
|---|---|
| GPU | NVIDIA RTX 5090 (32GB VRAM) |
| CPU | AMD Ryzen 9 9950X (16 cores) |
| RAM | 192GB DDR5 |
| vLLM | Nightly build (v0.14.0rc2) |
| Attention | TRITON_MLA (Multi-Head Latent Attention) |
Two vLLM configurations tested:
| Setting | Config 1 | Config 2 |
|---|---|---|
max-model-len |
8192 | 2048 |
max-num-seqs |
16 | 64 |
max-num-batched-tokens |
4096 | 2048 |
gpu-memory-utilization |
0.90 | 0.90 |
Conclusion
The snowstorm still has not arrived but it did hit 10F overnight. By morning, the pond outside my kitchen window was completely frozen over and a clear answer in the data appeared: AWQ trades a small amount of accuracy for meaningful throughput gains.
FP4 quantization preserves more model fidelity—the floating-point representation handles edge cases better than integer approximations. But AWQ’s mature Marlin kernels extract more performance from the hardware right now.
As FP4 kernel optimization matures (it’s a newer format, especially on Blackwell), this gap may narrow. For today, the choice is clear: accuracy-sensitive work gets NVFP4, throughput-sensitive work gets AWQ.
The space heater—I mean, GPU—continues its work.